4.1 Preprocesamiento en RapidMiner

La idea de este apartado es practicar todos los conceptos (o la mayoría) vistos en el punto 4 Preprocesamiento con los operadores que provee la herramienta RapidMiner (RM).
Para ello si deseamos aprender sobre ellos, la forma más fácil y práctica es analizar los ejemplos que nos provee por defecto la herramienta, para después aplicarlos en los problemas que sean de nuestro interés.
A continuación analizaremos los operadores de RM que se aplican en los conceptos vistos previamente.
Operador: Replace Missing Values
Este operador reemplaza los valores faltantes de los atributos seleccionados (del dataset de trabajo) por un reemplazo especificado.
Para obtener el ejemplo, debemos ir a:
Repository ==> Samples ==> processes ==> 02_Preprocessing ==> 07_MissingValueReplenishment, hacemos doble clic en este último y podemos observar el ejemplo.

El Operador "Retrieve" me permite acceder a información almacenada en el Repositorio, en este caso es a "../../data/Labor-Negotiations" y cargarla en el Proceso.
Antes de continuar creamos un punto de BreakPoint (o punto de Parada o Ruptura), para ello nos posicionamos en el operador Retrieve, hacemos clic con el botón derecho sobre el mismo y elegimos Breakpoint After, esto nos permitirá realizar pequeñas "pausas" en nuestro proceso e ir observando resultados previos.

Al hacer esto, podemos observar, un recuadro rojo con una flecha en ese operador, lo cual nos está indicando que un punto de BreakPoint en el mismo.

Al posicionarnos sobre el operador "Replace Missing Values", en el apartado de parámetros podemos observar:

El operador se llama "Replace Missing Values" pero se ha cambiado su nombre por Preprocessing.
El tipo de filtrado por atributo es "all", eso significa que se reemplazará todos los atributos que no tengan ningún valor, también se puede observar debajo, que se reemplazarán con el valor "average" (promedio).
Esta pestaña tiene otras opciones tales como "single" para un solo atributo, "subset" para un conjunto de atributos, etc.
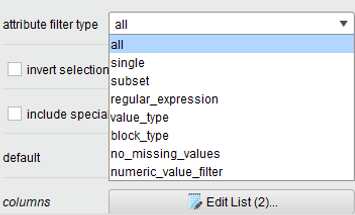

Si seleccionamos, "Show advanced parameters", nos aparece la opción "Edit List" en "columns", podemos observar que se editaron 2 columnas (a todas las demás se las reemplazó con el valor promedio), la columna salario-inc-1ro se reemplaza con el valor mínimo de esta columna y salario-inc-3ro se reemplaza con el valor máximo.

Si corremos el proceso (con la flecha o con F11) podemos observar:

(este es el punto de BreakPoint que definimos previamente, es por eso que en cabecera puede observarse "ExampleSet(Retrieve)") existen varios atributos con datos faltantes wage-inc-1st, wage-inc-2nd, etc.

Si corremos nuevamente podemos observar que los valores faltantes del atributo sueldo 1 se reemplazó con el valor mínimo de ese atributo, en este caso con 2. Los valores faltantes del atributo sueldo 2 se reemplazaron con 5100. Los valores faltantes de sueldo 3 se reemplazaron con 3913, el cual era el valor promedio para dicho atributo.
¿En que casos nos conviene reemplazar los valores faltantes?

Todo depende, en base a nuestra experiencia, del tipo y la importancia de los datos que se estén analizando. Si son datos críticos quizás lo mas conveniente sea no considerar esos registros o ignorarlos. Pero en muchas situaciones la eliminación de esos registros tal vez haga imposible la aplicación del modelo por la cantidad de registros en estudio, y en ese caso convenga reemplazarlos con el valor promedio.
También habría que considerar si ese atributo interviene o no en la aplicación del modelo. Es por ello que afirmarnos que no existe una única regla a aplicar, pero que en caso de emplear este operador es necesario un cuidadoso estudio previo que nos garantice el mejor reemplazo.
Operador: Map
Este operador cambia los valores determinados de atributos por otros que nosotros especifiquemos. Este operador se puede aplicar tanto a atributos numéricos como nominales.
Para obtener el ejemplo que trataremos a continuación, debemos ir a:
Operators ==> Map ==> Help ==> Jump to Tutorial ==> Mapping multiple values
Al hacer esto nos aparecerá el siguiente ejemplo.


Si hacemos doble clic sobre el operador Retrieve podemos observar que el dataset del cual obtuvo los datos se llama Golf, que corresponde a un archivo que nos indica con algunos ejemplos en que casos se juega al golf
Si nos posicionamos en el operador "Map" y hacemos clic en "Select Atributes" podemos observar los dos atributos seleccionados o sea aquellos que están a la derecha, es decir Outlook (pronóstico) y Wind (viento).
Estos son los atributos sobre los cuales haremos conversiones.
Hay que tener en cuenta que puede ser un único atributo o un conjunto de ellos (ver que figura subset) en atribute filter type.

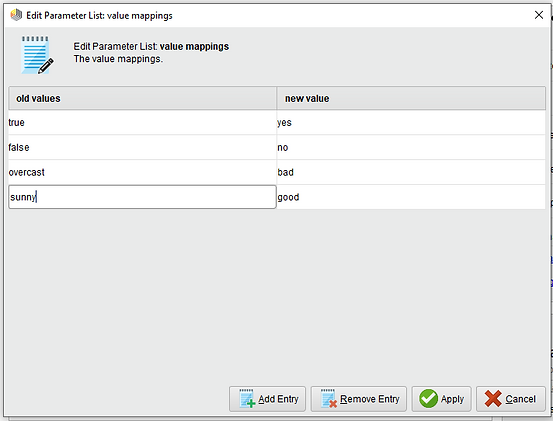
Si hacemos clic en "Edit List" podemos observar los valores de conversión, a la izquierda los valores anteriores o viejos y a la derecha los valores nuevos que les asignaremos.
Es decir los valores de los atributos iguales a "true" se cambian a "yes", "false" a no", "overcast" (nublado) a "bad" y "sunny" (soleado) a "good".
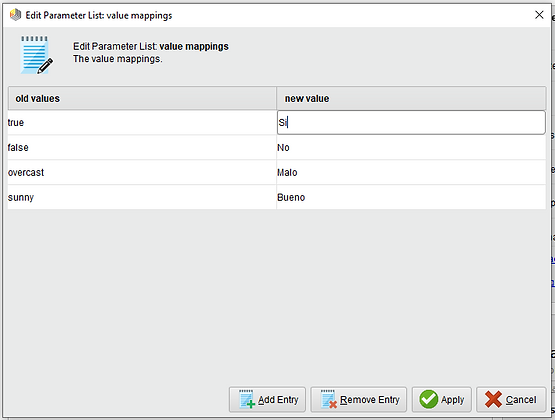
Solo a modo de práctica vamos a cambiar los valores nuevos de:
"true" a "Si"
"false" a "No"
"overcoast" a "Malo" y
"sunny" a "Bueno"


Agregamos un BreakPoint en Retrieve para observar los resultados.

Cuando corremos el modelo podemos observar los valores que tienen los atributos Outlook y Wind, estos son los valores originales de este DataSet.
Cuando continuamos con la corrida, podemos observar el resultado final, que en este caso es la conversión de los valores de los atributos Outlook y Wind.
En el atributo outlook vemos que se han convertido a "Bueno" y "Malo", y los demás valores que no estaban especificados se han convertido a "other".
En el atributo Wind los valores se han convertido a "Si" o "No" según corresponde.

Operador: Generate Atributes
Este operador permite construir nuevos atributos definidos por el usuario mediante expresiones y funciones permitidas por RM.
Para obtener el ejemplo que analizaremos, debemos ir a:
Repository ==> Samples ==> processes ==> 02_Preprocessing ==> 12_UserDefinedFeatureGeneration, hacemos doble clic en este último y podemos observar el siguiente ejemplo.


Si hacemos clic sobre el parámetro "Edit List" (o doble clic sobre el operador "Generation" podemos observar los tres atributos nuevos que se generaron:
sum = a1+a2
product = a3*a4, y
nested = (a1 + a3) * a4
Si hacemos clic en la calculadora que aparece a la derecha, podemos ingresar al Editor de Expresiones de Funciones, en la misma podemos observar a la derecha los atributos del DataSet y a la izquierda las funciones permitidas por RM:
-
Funciones Lógicas
-
Funciones de Comparación
-
Funciones para tratamiento de textos
-
Funciones matemáticas
-
Funciones para manejo de fechas
-
Funciones de conversión
-
Funciones básicas (+, -, *, /, etc)
-
Funciones avanzadas
Una de las funciones a la que deberías prestar especial atención es al "If" de las funciones lógicas, el cual permite según una condición tomar un valor u otro.

Continuando con nuestro ejemplo, agregamos un BreakPoint en Retrieve para observar los resultados.


Al correr el modelo en el punto BreakPoint, podemos observar los atributos originales de la tabla, el número de la fila, el label y cinco atributos más (a1, a2, a3, a4 y a5), todos numéricos.
Si continuamos la corrida del modelo, vemos que además de los atributos anteriormente mencionados se han generado tres nuevos atributos:
-
sum
-
product
-
nested

Discretización
Hay varios operadores que se pueden aplicar para realizar discretización, comparemos los disponibles por RM y después analicemos la aplicación de uno de ellos.
Discretize by Size: Discretiza atributos numéricos en bins (o contenedores) con el número definido por el usuario para los de ejemplos contenidos.
Discretize by Binning: Discretiza los atributos numéricos seleccionados en un número de bins especificado por el usuario.
Discretize by Frequency: Convierte los atributos numéricos seleccionados en atributos nominales discretizando el atributo numérico en un número de bins especificado por el usuario.
Discretize by User Specification: Discretiza los atributos numéricos seleccionados en clases especificadas por el usuario.
Discretize by Entropy: convierte los atributos numéricos seleccionados en atrib.nominales. Los límites de los bins se eligen de modo que la entropía se minimice en las particiones inducidas.

Operador: Discretize by Frecuency
A continuación analizaremos el ejemplo "Discretize by Frecuency", para ello, debemos ir a:
Operators ==> Discretize by Frequency ==> Help ==> Jump to Tutorial ==> Discretizing the Temperature attribute of the 'Golf' data set by Frequency
Al hacer esto nos aparecerá el siguiente ejemplo.


En la sección de parámetros podemos observar:
atribute filter type: es single o sea que estamos trabajando con un único atributo
attribute: aquí se eligió el atributo Temperature, como el atributo a discretizar por frecuencia
number of bins: se colocó 3, es decir que el número de bins o contenedores con los que trabajaremos será de 3
Continuando con nuestro ejemplo, agregamos un BreakPoint en Retrieve para observar los resultados.


Al correr el modelo en el punto BreakPoint, podemos observar el atributo "Temperature" y ver el histograma de la misma.

Si continuamos la corrida del modelo, se puede observar como ha cambiado el atributo "Temperature" de numérico a nominal, y si hacemos un diagrama de barras de dicho atributo, observando que hay tres rangos: [-∞, 69.5], [69.5, 77.5], [77.5, ∞]
}}}{{´´


Operador: Normalize
Este Operador normaliza los valores de los Atributos seleccionados.
Para obtener el ejemplo que analizaremos, debemos ir a:
Repository ==> Samples ==> processes ==> 01_Normalization, hacemos doble clic en este último y podemos observar el siguiente ejemplo.


En la opción de parámetros podemos observar:0a
attribute filter type: aquí se indican los atributos que se normalizarán, en este esta puesto "all" o sea que se normalizarán todos los atributos
method: se coloca el método de normalización elegido, en este caso es Z-transformation. RM posee 4 métodos:
-
z_transformation
-
range transformation
-
proportion transformation e
-
interquartile range
Continuando con nuestro ejemplo, agregamos un BreakPoint en Retrieve para observar los resultados.

Al correr el modelo en el punto BreakPoint, podemos observar todos los atributos numéricos de la tabla "Iris".

Si continuamos la corrida del modelo, se puede observar como se han normalizado todos los atributos numéricos.
