3.1 Introducción a RapidMiner

Es un programa informático para el análisis y minería de datos.
Permite el desarrollo de procesos de análisis de datos mediante el encadenamiento de
operadores; esto significa que a través de una GUI (Interfaz Gráfica de Usuario) o de
línea de comandos o a través de procesos batch (o de lotes) o desde otros programas a través de API de Java, permite realizar análisis estadístico, minería de datos y análisis predictivo.
Es un software de tipo Open-Source con licencia GNU GPL, basado en java, que trabaja bajo las plataformas Windows y Linux, posee alrededor de 500 operadores que pueden ser combinados, utiliza el lenguaje de scripting XML para describir los operadores y su configuración; y posee una gran cantidad de extensiones (plugins) (Rapidminer, 2016).
Sin entrar en detalles de las diferentes versiones de RapidMiner, lo mas importante que debes tener en cuenta es que la versión gratuita que puedes descargar AQUI tiene como limitación trabajar solamente con 10.000 registros.
Los ejemplos que a continuación se desarrollan son realizados con la versión de RapidMiner Studio 9.7.
Pasos para probar por primera vez RapidMiner y pautas a tener en cuenta

1 Descargar u obtener la planilla o tabla o base de datos a trabajar
Sino vamos a trabajar con alguna de las tablas de ejemplo que provee RapidMiner, debemos indicarle a la herramienta el archivo de la fuente de datos.
Existen muchos repositorios de dataset, a continuación indicaremos dos con los que trabajaremos:
kaggle.com: es una subsidiaria de Google LLC, es una comunidad en línea de científicos de datos y profesionales del aprendizaje automático. Es una página muy recomendable y que se caracteriza por:
-
Además de tener Base de Datos gratuitas.
-
Posee tutoriales muy interesantes.
-
Se realiza competencias de Machine Learning.
UCI Machine Learning Repository: si bien no posee tantos datasets
como kaggle tiene muchos que son muy interesantes, y te
recomendamos que ingreses a esta página y lo veas.


Para esta primer aproximación con RapidMiner:
-
Ingresaremos a la página de kaggle.
-
Buscaremos "Netflix movies" para hacer nuestras pruebas.
-
Elegiremos el dataset correspondiente a "Netflix Movies and TV Shows"
-
Elegiremos la opción "Download" del menú y descargaremos el archivo correspondiente.

2 Ingresa a RapidMiner
Una vez que ingresaste a RapidMiner debes elegir "Blank Process"

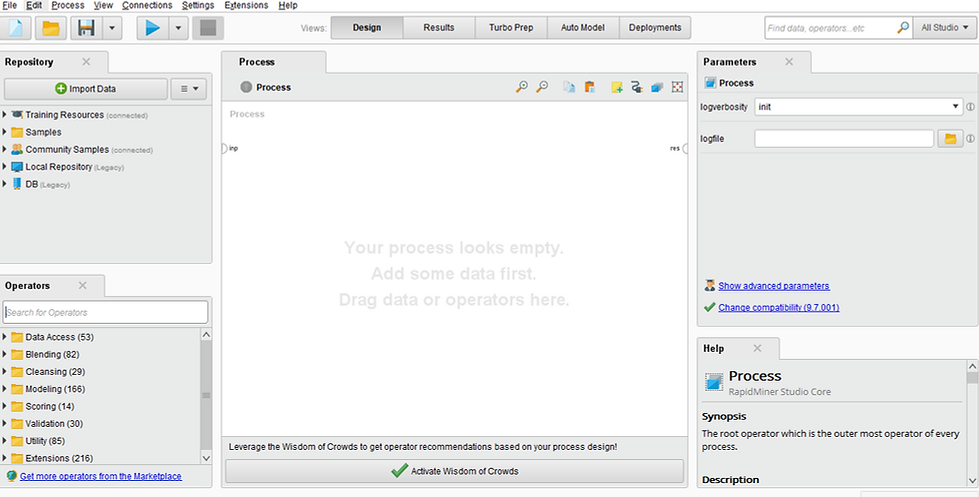
Fíjate las partes principales de la pantalla:
-
Importación de los Datos
-
Operadores
-
Las vistas: en este caso está marcado Diseño
-
Los parámetros
-
La parte central de los procesos o Main Process
3 Carga el dataset
En los operadores escribe "cvs" (es el tipo de archivo que leeremos en este caso).
Al hacerlo observarás que se hace un filtrado con los mismos.

Arrastra con el botón izquierda del mouse el operador "Read CSV" y arrástralo hacia la parte central de la pantalla o Main Process.
Pd: observa que hay un signo de admiración en el operador insertado, eso es señal de algún warning o advertencia.


Aquí hay dos formas de indicar el archivo CSV a trabajar:
-
Puedes indicar el archivo en csv file, o
-
Puedes seleccionar el botón "Import Configuration Wizard...". Es conveniente seleccionar esta segunda opción porque puedes marcar ciertos parámetros de importación, tal como te mostraremos a continuación.

Una vez seleccionado "Import Configuration Wizard...", seleccionaremos el dataset, en nuestro caso debería ser "netflix_titles.csv"

Al hacerlo, podemos observar una pantalla donde nos pide especificar el formateo de datos, y que al final hay un tilde donde nos señala que no hubo problemas. En nuestro caso lo dejaremos como está.
Antes de presionar Next podemos observar que existen varios signos de pregunta en la información que nos muestra esto es señal de datos ausentes.
Procedemos a presionar Next.

Para el archivo que elegimos debemos marcar la opción que dice "Replace errors with missing values", esto hace que los valores que producen errores sean reemplazados por valores faltantes.
Cuando te posiciones sobre la flecha que hay en cada atributo te aparecen una serie de opciones.

Primero cambiar el tipo de atributo, es decir considerarlo desde un primer momento poli nominal o real o fecha, etc.
Segundo cambiar el Rol. Esto es muy importante porque en problemas de predicción debemos cambiar el rol a "label". Esto significa que ese atributo será el objetivo de nuestro modelo.
Tercero renombrar la columna, lo que nos señala como veremos esa columna.
Y cuarto si queremos o no excluir ese atributo.
Video recomendado: Tutoriales RM: Leyendo una Hoja CSV y Explorando sus Datos