
Correlación
La correlación entre dos variables mide el grado de ajuste de la nube de puntos a la función matemática asignada. La relación entre dos variables puede ajustarse a una recta o a cualquier otra función matemática. Para medir el grado de ajuste de la distribución a una recta, se emplea el coeficiente de correlación de Pearson.
Características

-
Un coeficiente positivo y alto indica que ambas variables crecen o decrecen simultáneamente, es decir, presentan una fuerte correlación. Cuando mayor sea el coeficiente, más estrecho es la relación entre las variables.
-
Un coeficiente alto y negativo indica que cuando una variable crece, la otra decrece y viceversa, es decir, presentan una fuerte correlación inversa. Si el coeficiente es cero o próxima a cero indica que no existe relación entre las variables.
Matriz de Correlación
Una matriz de correlación es una tabla de doble entrada para los atributos del DataSet, que muestra una lista multivariable (la lista de atributos) horizontalmente y la misma lista verticalmente y con el correspondiente coeficiente de correlación llamado r o la relación entre cada pareja en cada celda, expresada con un número que va desde 0 a 1. El modelo mide y muestra la interdependencia en relaciones asociadas o entre cada pareja de variables y todas al mismo tiempo.

Ej. obtenido de Minería de Datos Aplicado a Sábanas Telefónicas (Actas CONAIISI 2017 pág.137). Este ejemplo es muy interesante porque muestra como aplicar la matriz de correlación al análisis de Sábanas Telefónicas provisto por las empresas de telefonía de Argentina.
Matriz de Co-Varianza
La matriz de covarianzas muestra los valores de covarianza, que miden la relación lineal de cada par de elementos o variables. A diferencia del coeficiente de correlación, la covarianza no es estandarizada.
Los valores de covarianza pueden encontrarse entre infinito negativo e infinito positivo y puede ser difícil interpretarlos. Para interpretar más fácilmente la relación lineal entre cada par de elementos o variables, utilice la matriz de correlación.
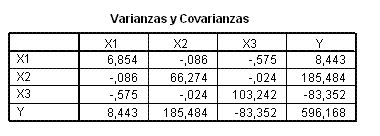
Características
-
Los valores de covarianza positivos indican que valores por encima del promedio de una variable están asociados con valores por encima del promedio de la otra variable y que valores por debajo del promedio de una variable están asociados con valores por debajo del promedio de la otra variable.
-
Los valores de covarianza negativos indican que valores por encima del promedio de una variable están asociados con valores por debajo del promedio de la otra variable.
Matriz de Confusión
Es una herramienta que permite la visualización del desempeño de un algoritmo que se emplea en APRENDIZAJE SUPERVISADO. Cada columna de la matriz representa el número de predicciones de cada clase, mientras que cada fila representa a las instancias en la clase real. Uno de los beneficios de las matrices de confusión es que facilitan ver si el sistema está confundiendo dos clases.

Características
La otra diagonal (FP + FN) refleja los errores del clasificador: los falsos positivos (dice que es positiva pero en realidad no lo es), o los falsos negativos (dice que es negativo, pero en realidad es positivo).


Regresión Logística
La regresión Logística puede ser Simple o Múltiple.

Regresión Logística Simple
La Regresión Logística Simple (David Cox 1958) es un método de regresión que permite estimar la probabilidad de una variable cualitativa binaria en función de una variable cuantitativa. Una de las principales aplicaciones de la regresión logística es la de clasificación binaria, en el que las observaciones se clasifican en un grupo u otro dependiendo del valor que tome la variable empleada como predictor. Por ejemplo, clasificar a un individuo desconocido como hombre o mujer en función del tamaño de la mandíbula.
Aunque la regresión logística permite clasificar, se trata de un modelo de regresión que modela el logaritmo de la probabilidad de pertenecer a cada grupo. La asignación final se hace en función de las probabilidades predichas.
La existencia de una relación significativa entre una variable cualitativa con dos niveles y una variable continua se puede estudiar mediante otros test estadísticos tales como t-test o ANOVA (un ANOVA de dos grupos es equivalente al t-test).








SVM (Support Vector Machines o máquinas de vectores de soporte)
Dado un conjunto de ejemplos de entrenamiento se pueden etiquetar las clases y entrenar una SVM para construir un modelo que prediga la clase de una nueva muestra.
SVM es un modelo que representa a los puntos de muestra en el espacio, separando las clases a 2 espacios lo más amplios posibles mediante un HIPERPLANO de separación definido como el vector entre los 2 puntos, de las 2 clases, más cercanos al que se llama vector soporte. Cuando las nuevas muestras se ponen en correspondencia con dicho modelo, en función de los espacios a los que pertenezcan, pueden ser clasificadas a una u otra clase.
SVM construye un HIPERPLANO o conjunto de HIPERPLANOS en un espacio de dimensionalidad muy alta (o incluso infinita) que puede ser utilizado en problemas de clasificación o regresión. Una buena separación entre las clases permite una clasificación correcta.

El problema de clases no linealmente separables se da cuando no hay forma de encontrar una HIPERPLANO que permita separar dos clases, en estos casos las clases no son linealmente separables. Para resolver este problema se usa el truco del kernel.
El truco del kernel consiste en inventar una dimensión nueva en la que se puedan encontrar un HIPERPLANO para separar las clases, tal como muestra en la figura de la derecha, en la cual se puede separar fácilmente las dos clases con una superficie de decisión.

Mencionaremos a continuación algunos casos de éxito, en donde se emplea SVM:
-
Reconocimiento óptico de caracteres.
-
Detección de rostros para que las cámaras digitales enfoquen correctamente.
-
Filtros de spam para correo electrónico.
-
Reconocimiento de imágenes a bordo de satélites (saber qué partes de una imagen tienen nubes, tierra, agua, hielo, etc.)

Importante: actualmente las redes neuronales profundas tienen una mayor capacidad de aprendizaje y generalización que los SVM.
Validación cruzada o cross-validation es una técnica utilizada para evaluar los resultados de un análisis estadístico y garantizar que son independientes de la partición entre datos de entrenamiento y prueba.
Repite y calcula la media aritmética obtenida de las medidas de evaluación sobre diferentes particiones. Se utiliza en entornos donde el objetivo principal es la predicción y se quiere estimar la precisión de un modelo que se llevará a cabo a la práctica.
